Kafka to HelixDB
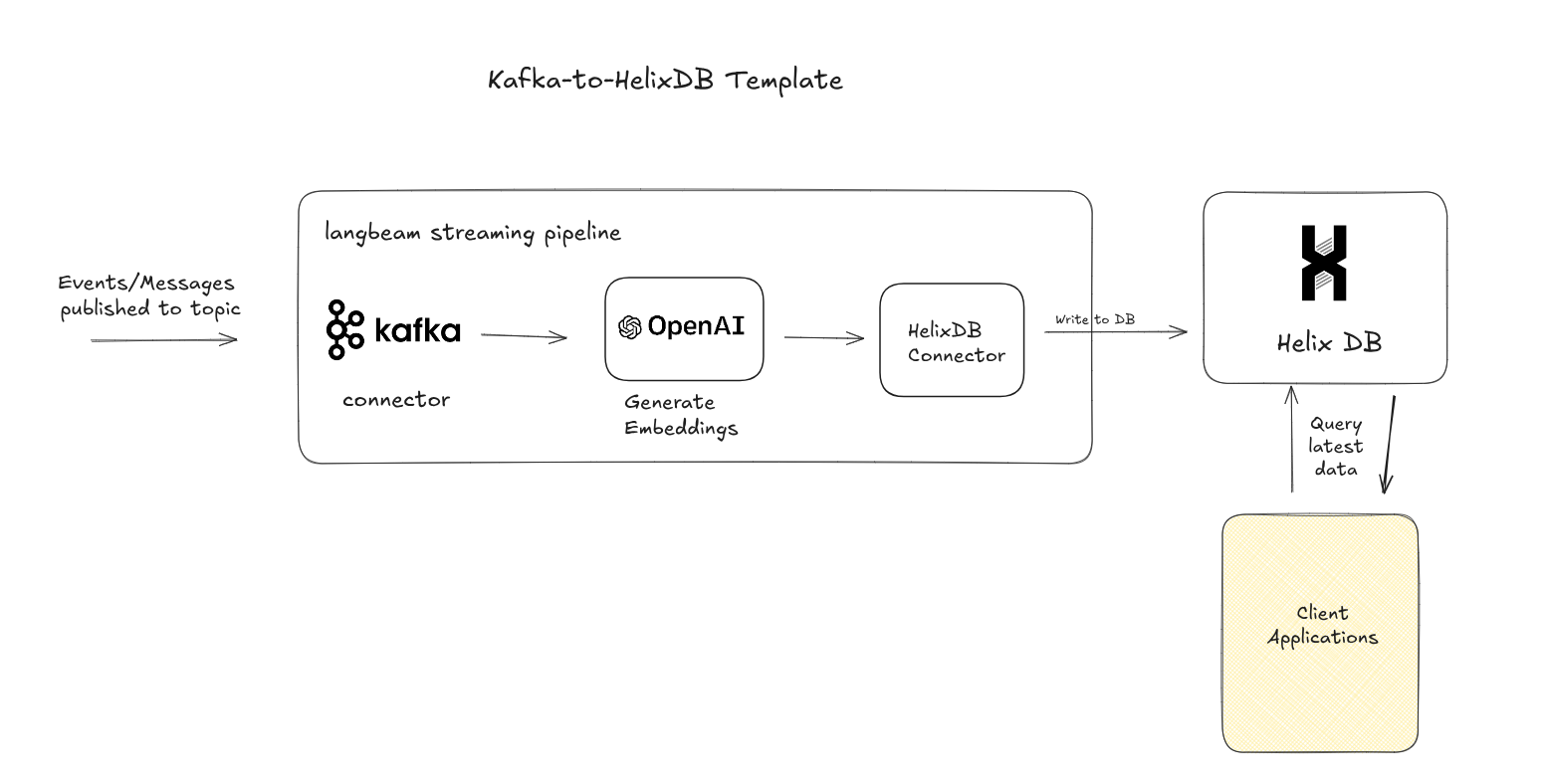
The Kafka to helixdb Pipeline is a pre-built Apache Beam streaming pipeline that lets you consume real-time text data from Kafka topics, generate embeddings using OpenAI models, and store the vectors into HelixDB node for similarity search and retrieval. The pipeline automatically handles windowing, embedding generation, and upserts to HelixDb's endpoint.
What It Does 🛠️
This template:
- Consumes streaming text data from Kafka topics in real-time
- Applies windowing to batch messages for efficient processing (10-second fixed windows)
- Generates embeddings using OpenAI embedding models via the LangchainBeam library
- Writes vector embeddings to HelixDB instance's endpoint
Use Cases 📦
- Real-time semantic search indexing
- Live recommendation systems
- Real-time knowledge base updates
- Event-driven vector database population
Template Parameters ⚙️
| Parameter | Description | Type |
|---|---|---|
brokers | Kafka bootstrap servers, comma-separated (e.g., broker_1:9092,broker_2:9092) | Required |
topic | Kafka topic to consume messages from (e.g., text-content, documents) | Required |
kafkaUsername | Kafka username or API key | Optional |
kafkaPassword | Kafka password or API secret | Optional |
kafkaSecurityProtocol | Security protocol: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL | Optional |
kafkaSaslMechanism | SASL mechanism: PLAIN, SCRAM-SHA-256, SCRAM-SHA-512 | Optional |
embeddingModel | OpenAI embedding model name (e.g., text-embedding-3-small) | Required |
openaiApiKey | Your OpenAI API key for embedding generation (e.g., sk-proj-...) | Required |
helixEndpoint | HelixDB query endpoint | Required |
helixUrl | Host URL of your HelixDB instance | Required |
Pipeline Architecture 🏗️
This pipeline continuously consumes messages from a Kafka topic using Apache Beam’s KafkaIO connector. It’s set up to read new messages arriving after the pipeline starts. The pipeline currently expects both message keys and values as plain strings, deserialized using Kafka’s StringDeserializer. Incoming messages are grouped into fixed 10-second windows for batch processing and limit the frequency of calls to external services like OpenAI and HelixDB, helping to prevent overload. Each message’s content is sent to an OpenAI embedding model via LangchainBeam, which generates vector embeddings. These embeddings are then upserted into a HelixDB query endpoint
some kafka clusters might be setup up with different serialization formats such as Avro, which typically requires integration with a schema registry to manage schemas, others may use different Kafka authentication mechanism. While these are not yet supported in this template, we plan to add them soon. We welcome your feature requests and contributions; please open an issue on GitHub repository to share your ideas.
Kafka Cluster Authentication
If your kafka cluster is managed service like confluent cloud, Amazon MSK then kafka connector in pipeline needs to authenticate with the brokers to read data from topics. The pipeline supports standard Kafka authentication parameters (kafkaUsername, kafkaPassword, kafkaSecurityProtocol, and kafkaSaslMechanism) for secure connection. If authentication parameters are not provided, the template defaults to connecting without authentication.
OpenAI API Calls and Batching
Currently, even though the pipeline groups messages into fixed 10-second windows to control processing frequency, it still sends embedding requests individually for each message within those windows. This means the number of OpenAI API calls scales with message volume, which may impact cost and rate limits.
In future updates, we plan to implement true batch embedding calls—sending multiple messages in a single API request—to significantly reduce the number of calls, lower costs.
HelixDB ingestion endpoint
At present the pipeline the supports writing the content and its embeddings into the endpoint So, make sure that your helix query(endpoint) that you'll be passing in pipeline options doesn't take any additional properties or metadata. Also the name the parameters as vector and content with its data types.
Example ingestion query:
QUERY InsertVector (vector: [F64], content: String) =>
document <- AddV<Document>(vector, { content: content })
RETURN document
How to Run 🚀
You can deploy this streaming pipeline using the Beam runner of your choice.
1. Google Cloud Dataflow
This pipeline is built and packaged as a Dataflow Flex Template, and the template file (gs://langbeam-cloud/templates/kafka-to-helixdb.json) is publicly accessible. This means you can run it directly in your own GCP project by using the gcloud CLI with appropriate parameters.
The pipeline source code is fully open source on GitHub. You're free to fork the repository, customize the pipeline, rebuild it as a Flex Template, and deploy it using your own GCP infrastructure.
Run Template:
gcloud dataflow flex-template run "kafka-to-helixdb-stream" \
--template-file-gcs-location="gs://langbeam-cloud/templates/kafka-to-helixdb.json" \
--region="us-east1" \
--project="your-project-id" \
--network="default" \
--subnetwork="https://www.googleapis.com/compute/v1/projects/project-id/regions/us-east1/subnetworks/default" \
--staging-location="gs://your-stage-bucket/stage/" \
--temp-location="gs://your-stage-bucket/temp/" \
--parameters="brokers=your-kafka-cluster:9092,topic=text-content,kafkaUsername=api_key,kafkaPassword=password,kafkaSecurityProtocol=SASL_SSL,kafkaSaslMechanism=PLAIN,embeddingModel=text-embedding-3-small,openaiApiKey=your_openai_key,helixEndpoint=InsertVector,helixUrl=https://host-name:6969"
If you'd like to host the template in your own GCP project:
-
Fork the Langchain-Beam repo and clone it locally.
You’ll find thekafka-to-helixdbtemplate under thetemplates/directory. -
Build the template using Maven:
mvn clean package -Prunner-dataflow -
Use the
gcloudCLI to run Dataflow Flex Template Build command.
This will:- Push your pipeline JAR as a container image to Artifact Registry
- Generate a
template.jsonfile in your GCS bucket, which acts as a pointer to your pipeline image and contains configuration metadata
gcloud dataflow flex-template build gs://your-bucket/templates/kafka-to-helixdb.json \
--image-gcr-path=us-docker.pkg.dev/your-project/your-repo/kafka-to-helixdb:latest \
--jar=/your-folder-path/langchain-beam/templates/kafka-to-helixdb/target/kafka-to-helixdb-dataflow.jar \
--env=FLEX_TEMPLATE_JAVA_MAIN_CLASS=com.templates.langchainbeam.KafkaToHelixDb \
--flex-template-base-image=JAVA17 \
--metadata-file=/your-folder-path/langchain-beam/templates/kafka-to-helixdb/src/main/metadata/metadata.json \
--sdk-language=JAVA
Now the template is built and hosted your GCS path. you can pass GCS template file to run command to execute the template on dataflow
2. Apache Flink
If you have an Apache Flink standalone cluster, you can submit the template as a job using the prebuilt Docker image.
Note: Don’t have a remote Flink cluster? No problem! You can quickly spin up Flink on your laptop in just 3 simple steps and run templates locally.
Submitting Job
Once your Flink cluster is up and running, you can submit a template as a job using Docker.
Run the following command, adjusting the pipeline options as needed:
docker run --rm \
-e FLINK_MASTER=host.docker.internal:8081 \
-e FLINK_VERSION=1.18 \
us-docker.pkg.dev/ptransformers/langbeam-cloud/templates/flink/kafka-to-helixdb:latest \
--runner=FlinkRunner \
--brokers=your-kafka-cluster:9092 \
--topic=text-content \
--kafkaUsername=key \
--kafkaPassword=secret \
--kafkaSecurityProtocol=SASL_PLAINTEXT \
--kafkaSaslMechanism=PLAIN \
--embeddingModel=text-embedding-3-small \
--openaiApiKey=your_openai_key \
--helixEndpoint=InsertVector \
--helixUrl=https://host-name:6969
How It Works
The pipeline is built and packaged as a JAR. Since Apache Beam’s Flink Runner must be compatible with your Flink version, there are multiple JARs available—each tailored to a specific Beam and Flink version combination. Refer to the Flink version compatibility matrix to choose the correct version.
-
The container downloads the appropriate .jar file from GCS based on FLINK_VERSION (your flink cluster version) with correct beam and runner dependencies
-
It uses the Flink CLI (flink run) to submit the job to the Flink cluster (as specified by FLINK_MASTER - Flink cluster Url )
-
All dependencies—including Java 17 and the Flink CLI—are preinstalled in the image, so you don’t need to set up anything else.
3. LangBeam (Managed Cloud)
LangBeam is a fully managed platform for running Apache Beam pipelines, such as this Kafka-to-helixdb template. Instead of dealing with infrastructure setup, runner configuration, provisioning resources, and scaling. You simply provide the required template parameters and start the pipeline.
From that moment, your AI agents and RAG applications begin receiving real-time data — continuously, reliably, and at scale.
Sign up for early access.
4. Locally
You can also run the template locally using the Apache Beam DirectRunner. This is useful for testing, debugging, or running small jobs without setting up a full cluster.
Prerequisites:
- JDK 17
- Maven
Run with Maven
Clone the repository:
git clone https://github.com/Ganeshsivakumar/langchain-beam.git
cd langchain-beam/templates/kafka-to-helixdb
Build the template:
mvn clean package -Prunner-direct
Run with direct runner:
java -cp target/kafka-to-helixdb-direct.jar \
com.templates.langchainbeam.KafkaToHelixDb \
--runner=DirectRunner \
--brokers=localhost:9092 \
--topic=my-topic \
--kafkaUsername=key \
--kafkaPassword=secret \
--kafkaSecurityProtocol=SASL_PLAINTEXT \
--kafkaSaslMechanism=PLAIN \
--embeddingModel=text-embedding-3-small \
--openaiApiKey=your_openai_key \
--helixEndpoint=InsertVector \
--helixUrl=https://host-name:6969
Template Support 🧰
This template is fully open source and part of the Langchain-Beam project.
Feel free to:
-
🔧 Fork and customize the template to suit your specific use case, deploy it on your own infrastructure, or extend it to support new LLMs, embedding providers, or output formats.
-
🌱 Submit a PR if you'd like to contribute improvements, add new features, or even create entirely new templates for other vector DBs or embedding models.
-
🐞 Create an issue if you run into any problems running the template on Flink, Dataflow, or locally — we're happy to help troubleshoot!